Container Managed Models-Enterprise JavaBeans - Part 8
26 Dec 1998Container-Managed-Models
Modeling Using Session and Entity Beans
In general, session beans are about a conversation with a client and entity beans are about records in the domain model.
-
Use entity beans for a persistent object model (to act as a JDBC wrapper, for instance) giving the rest of your application an object-oriented interface to your data model. Session beans are for application logic. For example, use session beans to model the layer that interfaces with your object-model but normally should not go direct to your database. Thus, a set of session beans provide all the functionality for a particular application of which several could be communicating with the entity-based object model. It will be session bean’s EJBObjects that communicate with the front-end GUI code (or servlets, and so forth). Be aware, however, that entity beans can also have an object model behavior. As always, no hard and fast rules exist about this; it depends on your particular scenario.
-
Use session beans as the only interface to the client, providing a “coarse grained” facade to the underlying model. You should use entity beans to enforce the accuracy/integrity of databases, not merely as an object representation of data. Then use session beans to run the processes that operate on the databases. This split reduces the pain of introducing new/changed processes because testing needn’t be as stringent.
-
Insist on reuse of entity beans. Although they may initially be hard to develop, over time they will prove a valuable asset for your company.
-
Expect little reuse of session beans. Plan instead to discard them and create new ones quickly by building a RAD capability around them.
-
Elevate entities to a much higher level. Entities are good candidates to model business objects/domain objects, which have a unique identity and need to be shared by various clients and be persisted over a longer time. They can also incorporate the business logic that goes on with their responsibility. Session beans can be used whenever a business method requires services from two or more entities. A good idea is to have all interfaces to the system through session beans.
To summarize:
- Use session beans for application logic.
- Use session beans as the only interface to the client.
- Expect little reuse of session beans.
-
Use session beans to control the workflow of a group of entity beans.
- Use entity beans to develop a persistent object model (wrap all your JDBC code).
- Use entity beans to enforce accuracy/integrity of your database.
- Insist on reuse of entity beans.
- Use entity beans to model domain objects with a unique identity shared by multiple clients.
EJB Container
A container is a set of classes generated by the deployment tool that manages, among other things, an enterprise bean’s persistence, transactional properties, and security.
Obtaining Services from the Container
The EJB container provides EJBs with a distributed object infrastructure. EJB assumes an underlying ORB that understands the CORBA/IDL or RMI/IDL semantics. The IIOP transport layer should be able to propagate CORBA OTS transactions.
The container helps in component packing and deployment. An EJB is packaged using manifests, JARs, and deployment descriptors. The container un-JARs the EJBs and then executes it based on the instructions it gets from the manifest file and deployment descriptors
EJB containers provide declarative transaction management by enabling you to define your transactional objects. Although EJB supports transactions built around the JTS service, your application need not make explicit calls to JTS to participate in a distributed transaction. The EJB container can explicitly manage the start, commit, and rollback of a transaction. It can also start a transaction if none exist and manage its completion using the underlying JTS services. You design the transactional attributes of the EJB at design-time (or during deployment) using declarative statements in the deployment descriptors. Optionally, EJBs can explicitly control the boundaries of a transaction using explicit JTS semantics.
EJB containers manage the entire lifecycle of a bean. As a bean provider, you are responsible for providing a remote interface for your EJB. You must also define a factory interface that extends the javax.ejb.EJBHome factory object. The interface should provide one or more create() methods, one for each way you create your EJBObject. The container provider automatically generates the factory implementation. However, your enterprise Bean must implement an ejbCreate() method for each create() method you defined in your factory interface. As a last step, you must register your factories with the container so clients can create new beans. The container also provides a finder interface to help clients locate existing entity beans.
As part of managing the lifecycle of an enterprise bean, the container calls your bean when it is loaded into memory (or activated) and also calls it when it is deactivated from memory (passivated). Your component can then use these calls to manage its state explicitly and allocate or release system resources.
EJB containers can manage both transient enterprise Bean and persistent enterprise Beans. Persistent or entity beans encapsulate in their object reference a unique ID that points to their state. An entity bean manages its own persistence by implementing the persistence operations directly. The container just hands down a unique key and tells it to load its state. The entity EJB can also direct the EJB container to manage its state. The container can do this simply by serializing the enterprise Bean’s state and storing it in some persistent store. Or, it can be as sophisticated as to map the enterprise Bean’s persistent fields to columns in an RDBMS. Alternately, the EJB container may choose to implement persistence using an embedded ODBMS. The more advanced EJB containers can load the state of an enterprise Bean from a persistent store and later save it on transactional boundaries.
EJB containers can provide metadata about the enterprise Beanthey contain. For example, the EJB container can return the class name of the enterprise Bean with which this factory (EJBHome) interface is associated.
EJB containers automate the management of some of the security aspects of the enterprise Bean. The EJB developer gets to define the security roles for his EJB in a SecurityDescriptor object. The developer then serializes this object and puts it in his bean’s JAR. The EJB container uses this object to perform all security checks on behalf of the EJB.
Relationship Between EJB Container and the Server
The interface between the container and the server isn’t specified yet, so it’s impossible at this point to have a container without a server. EJBs are intended to exist within an EJB container; they don’t run as standalone classes. The reason for this is the container provides the logical interface between the bean and the outside world; the server provides the implementation of the functionality the container requires (persistence, transactions, pooling, multiple instances, and so forth). The idea of the EJB architecture is the server and container are responsible for providing the hard stuff (transactions, persistence, and so forth), so you only have to write the business logic. With EJB, you don’t have to implement your own persistence mechanisms or explicitly deal with multithreading. Using EJB helps you avoid the truly hard parts of building distributed systems.
Building Customized EJB Containers
The EJB specification allows customization of the container. Beans that use customized containers naturally cannot be deployed within “vanilla” EJB containers, whereas the reverse is true (for example, regular EJBs can be deployed within customized EJB containers.) Because the specification also does not define the contract between the container and the server, the interfaces are proprietary to each server. To build a custom container, therefore, you need to work with the specific EJB server vendor.
Multiple reasons may exist for extending the EJB model for a given enterprise and create customized containers, however. The three reasons that come to mind are
- Extending the container-to-EJB contract for legacy integration or for including a service currently not modeled into EJB. An event service is one such glaring example.
- Viewing the legacy application as a persistence provider. No change occurs to the container-to-bean and container-to-EJB client contracts.
- Reimplementing the services used or provided by the EJB container. For example, integrating an organization’s custom middleware requires the EJB server to use the appropriate middleware. Again, no change occurs to any of the contracts per se.
If you wish to achieve the componentization benefits of the EJB model, extension of the EJB contracts should be the recommended approach over writing custom containers from scratch. Theoretically, nothing is wrong with organizations implementing component models with entirely different interfaces/contracts other than the fact that the benefits that may stem from such componentization are limited to that organization.
Contract Between the Client and the EJB Container
The EJB provider must adhere to two contracts: the client contract and the component contract. The client contract is between the EJB client and the EJB container, and is actually the view the client sees of the enterprise bean. It serves to establish a unique identity by defining the home interface and indicating how the class methods work. The JNDI defines how to search and identify the EJB and container objects uniquely. Within the container, a unique key identifies each EJB. The home interface is a basic description of how to create EJBs in various forms according to the different create() methods and how to destroy EJBs using the remove() method.
Two sides exist to the life cycle of an EJB client-server session:
- How the client sees the EJB
- How the EJB container and server facilitate the client
Figure 8 illustrates the classes involved in a typical EJB scenario. The sequence diagram is shown in the following
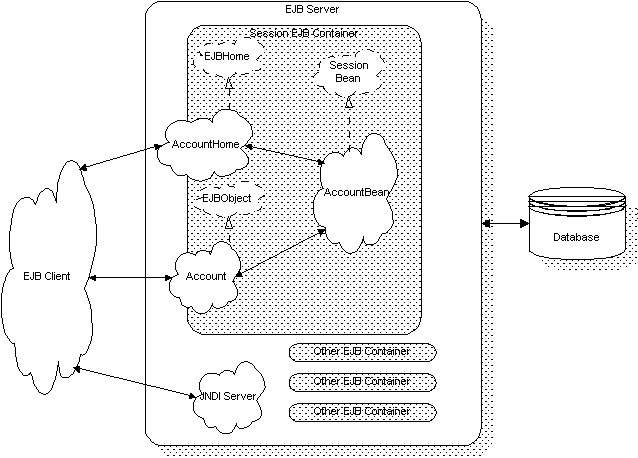
Figure 8: Classes available in a typical EJB scenario
The point of view of the client is illustrated in Figure 9.
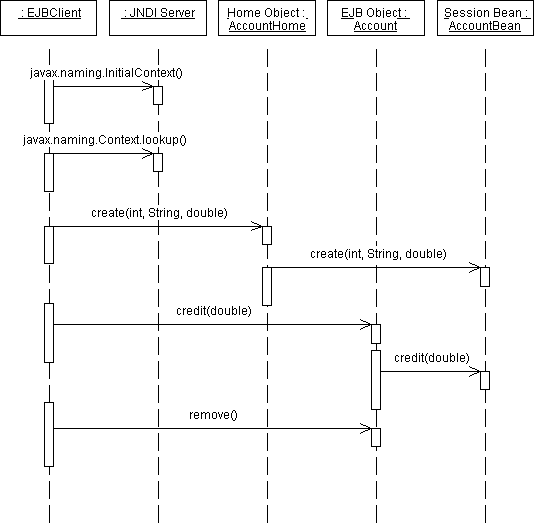
Figure 9: Client view of an enterprise JavaBean session
Starting at the top left of the image, the client first creates a new context to look up the EJBObject with the help of a JNDI server. Given this context, the client then creates an EJB using the home interface. The client can then call the available methods of the EJBObject. When all the activities are complete, the client calls the remove()method, also through the home interface, to terminates the session.
The equivalent code for the same looks like Listing 20:
import javax.naming.*;
public class EJBClient {
public static void main (String[] argv) {
// get the JNDI naming context
Context initialCtx = new InitialContext ();
// use the context to lookup the EJB Home interface
AccountHome home=(AccountHome)initialCtx.lookup("Account");
// use the Home Interface to create a Session bean object
Account account = home.create (1234, "Athul", 1000225.28d);
// invoke business methods
account.credit (1000001.55d);
// remove the object
account.remove ();
}
}
Listing 20: The EJB Client code to talk to an EJB
Contract Between a Container and an EJB
The component contract is between an EJB container and the EJB and defines a callback mechanism to the EJB instance for object state-management purposes. This allows the container to inform the EJB of events in its life cycle.
The EJB object and container’s point of view is shown in Figure 10 in simplified form. Both the EJB server and container perform actions, which are invisible to the client. The container allocation is a function of the EJB server and is neither the responsibility of the client nor the EJB programmer.
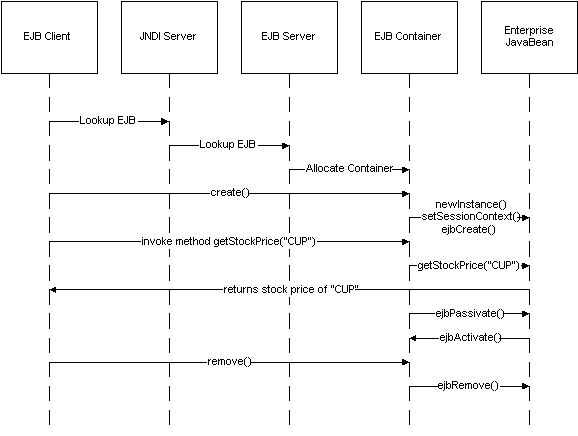
Figure 10: The container and enterprise JavaBean point of view of a session
The client begins a new session by sending the create() command. The container then creates a new enterprise bean using the newInstance() call and proceeds to define the context in which the enterprise bean will run with setSessionContext(). Elements of the context include: information about the container, the environment, and the calling client’s identity. Finally, it sends the ejbCreate() call, which contains the input parameters as sent by the client. This creates a new enterprise bean whose methods can be accessed directly without any interference from the container.
In some cases, the container may choose to push EJB instances into a secondary cache when they are idle, using the ejbPassivate() call. When the EJB session object is needed again, it is recalled with ejbActivate(). When the client has completed its session, it sends the destroy() call, which is intercepted by the container. The container, in turn, sends a ejbDestroy() call to the EJB instance, allowing it to clean up any pieces as needed.
The container can do a lot more than just pass operations safely to an EJB instance. Where many session objects exist in parallel, for example, the container can manage concurrency for maximum efficiency service. The container can cache an EJB instance in secondary memory if it is idle for too long. This reduces the overall memory usage while preserving the EJB session and its state. The container can also use the number of incoming connections to predict how many additional sessions may be needed in the future and allocate them ahead of time, thus saving on connection setup time.
The capability to cache an EJB session object is not the same as with a persistent object. This cache is lost when the EJB server is shut down or crashes, or if the container is destroyed. It’s a temporary cache system that exists only to enhance performance when the program has to handle a large number of session objects.
The container manages this working set of session objects automatically without the client or server’s direct intervention. There are specific callback methods in each EJB which describes how to passivate (store in cache) or activate (retrieve from cache) these objects. When the ejbPassivate() call is made, the EJB is serialized using the Java serialization API or other similar methods and stored in secondary memory. The ejbActivate() method causes just the opposite.
EJB Servers
An EJB application server is a prerequisite for using EJBs. It is an integral component of the EJB architecture—the EJB containers run within the application server. Generally speaking, the primary goals of an application server are to improve performance and to simplify development. An application server combines the capabilities of a TP monitor with distributed object technology.
The most important feature in a TP monitor and, likewise, within an application server, is efficient resource management. Application servers pool and recycle expensive system resources such as network connections, processes, threads, memory, and database connections. As a developer, you don’t want to write your own thread management and synchronization services within your application code. You don’t want to write code within your application to initialize database connections, cache them in a pool, and then allocate them to other applications as needed. You want the application server to do that for you.
EJB increases the simplicity level even more than a plain application server. EJB automates complicated middleware services such as transactions, security, state management, and persistence.
Distributed objects need to know where to find each other using naming services, whom to trust using appropriate security, and how to manage their life cycles. Services such as naming services, distributed transaction control, security mechanisms, remote access, persistence, resource pooling or threading, instance pooling and concurrency issues, and so forth are automatically handled (and built into) by the EJB server. Additionally, EJB also defines some design patterns and naming conventions.
Note
Notice I have not talked about database connection pooling in the previous paragraph. While the current EJB specification does talk about instance pooling, it has nothing to say about connection pooling. To see how these instance management algorithms work, think about the EJB component instance as living inside the EJB container. When a method request travels from the client outside the container to the component instance, it must travel through the container. The container intercepts the method before it is delivered to the enterprise bean. This gives the container an opportunity to participate in the delivery of that request. And one of the ways the container can participate is by injecting an instance management algorithm into that delivery.
Instance management is about faking out the client. The client code thinks it has a dedicated middle-tier instance, just waiting for the next client request. But the client has no idea whether an actual middle-tier instance really exists. All the client knows is this: By the time the method is actually delivered by the container, something needs to be there to receive that method.
Instance Pooling and EJB
EJB uses an instance management algorithm called Instance Pooling (IP). In the IP algorithm, the middle-tier instances are themselves pooled, not the database connections. After the method has been intercepted by the container, and before it has been delivered to the enterprise bean instance, the container does not create a brand new instance to process the request—it uses one from a pool of instances. When the instance has finished processing the method, the container does not destroy it. Instead, it is returned to the pool.
Because the IP algorithm does not constantly create and destroy instances, it needn’t worry about the efficiency of creating and destroying database connections. Certainly, the actual creation of the instance may sometimes be slow, but that happens infrequently.
The IP code moves the creation and destruction of the database connection out of the business logic and into the methods executed when the instance is first created during ejbActivate() and finally destroyed during ejbPassivate().
In EJB, the actual middle-tier EJB component instance may be pooled. Since the component may not be running all the time, it does not use up a lot of system resources.
As soon as the call comes in from the client, the EJB container may use an EJB component instance from a pool of shared instances. And as soon as the request is serviced and the reply is sent back to the client, the actual EJB component is returned back to the pool. It may not be destroyed.
Generally, this is what happens on the Server when a client requests services from a typical stateless EJB component:
- Read the component’s state from the database.
- Perform the business logic.
- Write the component’s changed state, if any, back to the database.
EJB isn’t stateless between calls from the client. For stateful beans the above scenario is true if and only if a call to the component coincides one to one with transaction boundaries. You can easily have the following scenario:
- Read the component’s state from the database.
- Perform the business logic.
- Return data to the client.
- Client makes 0-N more calls to the bean, performing business logic, and database operations.
- Write the component’s changed state, if any, back to the database.
IP is conceptually simple and has less algorithm dependent code in the business logic. In fact, even the read and write of the component state can be moved out of the business logic if this algorithm is coupled with transactional notification.
This is where the JDBC 2.0 specification could help because within it you’ll find built-in support for database connection pooling. This means any EJB product can use JDBC 2.0 for relational database access and the connection pooling can be portable across EJB container products.
Every EJB server implementation needs a runtime system, although the specification does not prescribe which one. It could be a database, it could be a legacy transaction system, or it could be CORBA-based. Currently, most EJB server implementations are based on JTS. JTS is to a large extent the Java mapping around CORBA’s Object Transaction Service (OTS) and takes care of the “plumbing” that needs to be accomplished when coming up with distributed enterprise solutions., We hope someday the server vendors will give us the best of both worlds by directly layering EJB servers on top of CORBA OTS/SSL. This should give us direct access to the myriad services of the CORBA platform via the easy-to-use APIs of the EJB specification.
Server Infrastructure
The EJB server provides an organized framework for EJB containers to execute in. Some of the important services EJB servers typically provides are as follows:
Distributed transactional support
Distributed transaction management involves two possible layers of distribution: multiple application participants and multiple data resource managers. Each layer must be managed separately. JTS/OTS focuses on managing the multiple application participants, while XA and DTC focus on managing the multiple data resource managers.
In a distributed object environment, a single transaction may involve a number of different objects. One object starts the transaction and then it calls some number of methods in other objects to perform some work. When everything is complete, it commits the transaction. JTS/OTS defines an object, called the transaction context, which keeps track of all the object participants in the transaction. When the transaction commits, the OTS forwards the commit request to a transaction coordinator (TC) to manage the data resource managers. An OTS can provide its own TC or it can delegate it to a third party—either the transaction coordinator in a database or a separate distributed transaction coordinator (such as Microsoft’s DTC or an XA-compliant transaction coordinator like Encina or Tuxedo). Most EJB implementations (for example, WebLogic, Bluestone, Novera, Persistence, Oracle AS, and Oracle8i) use the database delegation approach and don’t support heterogeneous transactions. As of now, GemStone, Inprise, Secant, OrchidSoft, and IBM WebSphere are the only EJB servers that provide an integrated distributed TC service.Although EJBs can be used to implement nontransactional systems, the model was designed to support distributed transactions. EJB requires the application server to use a distributed transaction management system that supports two-phase commit protocols. EJB transactions are based on JTS. Individual enterprise beans do not need to specify transaction demarcation code to participate in distributed transactions. The EJB environment automatically manages the start, commit, and rollback of transactions on behalf of the enterprise bean. Transaction policies can be defined during the deployment process using declarative statements. Optionally, transactions can be controlled by the client application.
EJB Transaction Management
Each transaction is a set of atomic operations. In methods that have transactions in them, the method executes completely and commits or returns a failure notice. It’s also possible to undo the action using a rollback mechanism. These kinds of transactions are common in the database world because they help maintain coherency of content data. Each executed method functions as a separate transaction. Figure 11 shows how transactions are handled.
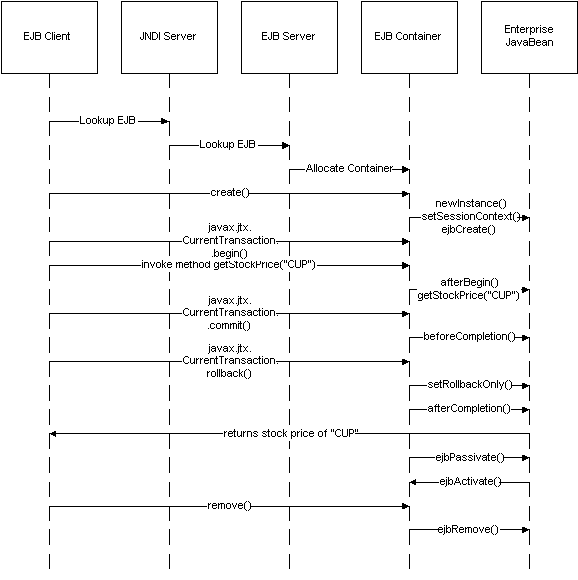
Figure 11: Transactional sessions
The basics of transactional programming are the same, except when calling the EJB’s methods. Figure 11 is a sequence diagram, which corresponds to the following code and shows what happens when the getStockPrice() method is invoked.
The following code snippet in Listing 21 is important because not only does it show how to build transactional code into your beans, but it also shows how to connect to a remote CORBA server object using EJBs.
import javax.ejb.*;
import javax.jts.UserTransaction;
import java.rmi.*;
import org.omg.CORBA.*;
import org.omg.CosNaming.*;
import Trader.*;
public class QuoteBean implements SessionBean {
SessionContext ctx;
public StockTrader trader;
public double getStockPrice (String company)
throws RemoteException {
// Code for Transactions in the enterprise bean
UserTransaction tx = ctx.getUserTransaction ();
tx.begin ();
double value = trader.getStockPrice (company);
if (value > 0)
tx.commit ();
else
tx.rollback ();
return value;
}
// Implement the methods mandated by the EJB Spec
public void ejbCreate () {}
public void ejbActivate () {}
public void ejbPassivate (){}
public void ejbRemove () {}
// Set the Session context and also get a reference to the
// Stock Trader CORBA server object running on a remote system.
public void setSessionContext (SessionContext ctx)
throws RemoteException {
this.ctx = ctx;
try {
// Create and initialize the ORB
ORB orb = ORB.init (args, null);
// Get the root naming context
org.omg.CORBA.Object objRef =
orb.resolve_initial_references ("NameService");
NamingContext ncRef = NamingContextHelper.narrow (objRef);
// Resolve the object reference in naming
NameComponent nc = new NameComponent ("NASDAQ", "");
NameComponent path [] = {nc};
trader = TraderHelper.narrow (ncRef.resolve (path));
} catch (Exception e) {
e.printStackTrace ();
}
}
}
Listing 21: How the QuoteBean session EJB, acts as a CORBA client
Before a method is called, the client needs to indicate a new transaction is starting using the javax.jts.UserTransaction.begin() call.
When a method is called by the client, the container signals the EJB instance with the afterBegin() call. The EJB then begins processing the method call.
At this point, one of two things can happen: The client may request the method call be committed or change its mind and execute a rollback. When the client requests the method be committed to action, the container informs the EJB it is ready to receive the information with the beforeCompletion() signal. When the EJB’s processing of the method call is complete and the action has been committed, the EJB first sends a response back to the client (if there is a response) and then the container sends the afterCompletion() signal, as True, to the EJB.
If the client changes its mind, it can execute a rollback call after the method call is started. The container sends a setRollbackOnly() signal to the EJB to undo whatever it may have done. When the rollback is complete, the container sends the afterCompletion() signal, as False, indicating to the EJB that it should reinitialize itself.
The passivation and activation methods defined in the EJB interface to the container work just the same as before with the exception that an EJB instance cannot be made passive while a transaction is in progress. One additional thing to note is that a transaction does not have to be limited to just one method call. In fact, typically a number of method calls are packaged inside a single transaction. This allows the client to execute complex operations while still reserving the ability to roll them all back in case of partial failure.
Multithreading and resource pooling
An enterprise bean is not allowed to use thread synchronization primitives. Hence, the keyword synchronized should never appear in an enterprise Bean implementation code.
The EJB specification allows the server to passivate an entity bean between methods—even within a transaction. This is to allow the server to perform scalable state management and resource pooling. When the container passivates bean X, it first calls ejbStore() to allow the bean to synchronize its updated state with the underlying database. When the container reactivates bean X in the future, it will ejbLoad() the state stored in the database. The loaded state is the state saved at the most recent ejbStore() by the transaction. Note, the database is doing all the necessary synchronization with other transactions free.
As far as threading is concerned, the EJB specification makes it explicitly illegal for an enterprise bean to start new threads. To ensure the system is manageable, the EJB server must control all thread creations. Allowing enterprise beans to start threads would lead to serious problems. For example, imagine two concurrent threads running with the same transaction context trying to access an underlying database. If one thread is reading data while the other thread is updating the data, it would be difficult to predict what data the first thread would read. Another problem is the EJB server will be unable to guarantee the X/Open checked transaction semantics because it would have little knowledge of whether all the threads involved in a transaction have terminated before the transaction’s commit starts.
Security
EJB server implementations may choose to use connection-based authentication in which the client program establishes a connection to the EJB server and the client’s identity is attached to the connection at connection establishment time.
The communication mechanism between the client and the server propagates the client’s identity to the server. However, the EJB specification does not specify how the EJB server should accomplish this. The getCallerIdentity() method should always retrieve the identity of the current caller.
The EJB/CORBA mapping prescribes this mechanism—it specifies the CORBA principal propagation mechanism be used. This means the client ORB adds the client’s principal to each client request.
If two EJB servers, X and Y, from two different vendors, both implement the EJB/CORBA mapping, it is possible for enterprise beans running on system X to access enterprise beans running on system Y, as if they were local enterprise beans (and vice versa). The transaction context will be properly propagated using the OTS propagation protocol between the transaction managers running at the two sites. The same applies to security, although one of the systems must provide mapping of principals.
The same level of interoperability exists between client systems and a server system. If both systems implement the EJB/CORBA mapping, they can interoperate even if they are from different vendors. This means, for example, if the EJB/CORBA client runtime becomes part of the JRE, and JRE is part of a browser, then the browser can run applets that are clients to any EJB server that implements the EJB/CORBA mapping. The downloaded applet only includes the application-specific client stubs, but not a server-specific ORB, transaction proxy, or EJB runtime. This level of interoperability was the primary motivation for doing the EJB/CORBA mapping.
CORBA/IIOP compatibility
While the EJB specification allows the EJB server implementers to use any communication protocol between the client and server, the EJB/CORBA mapping document is prescriptive with respect to what goes on the wire. This allows both system-level and application-level interoperability between products from vendors who choose to implement the EJB/CORBA protocol as the underlying communication protocol.
For example, Java clients have a choice of APIs—either the Java RMI or Java IDL. Non-Java clients can communicate with the server components using IIOP and the appropriate IDL language mapping. Clients using Microsoft’s COM+ protocol can also communicate with the server component through a COM-CORBA bridge. Interesting to note is the client of an EJB can itself be a server component when, for example, it is a servlet. In this case, even a browser client can make EJB invocations by means of an HTTP connection to the servlet.
Deploying EJBs
EJBs are deployed as serialized instances (*.ser files). The manifest file is used to list the EJBs. In addition to this, a deployment descriptor has to be supplied along with each .ser file. Deployment descriptors are serialized instances of a class. They are used to pass information about an EJB’s preferences and deployment needs to its container. The EJB developer is responsible for creating a deployment descriptor along with the bean. In this case, the deployment descriptors contain a serialized instance of an EntityDescriptor or SessionDescriptor.
A typical EJB manifest entry looks like Listing 22:
Name: ~gopalan/BankAccountDeployment.ser
Enterprise-Bean: True
Listing 22: A typical EJB manifest entry
The Name line describes a serialized deployment descriptor. The Enterprise-Bean line indicates whether the entry must be treated as an EJB.
Future trends
Currently, the EJB specification is Version 1.0 and provides an excellent architectural foundation for building distributed enterprise-level business systems. Although the specification authors did well to delegate lots of low-level details to specific implementers, some areas need to be addressed. For instance, the EJB model for handling persistent objects can be improved. Standardizing the contract between development tools and systems to provide a uniform debugging interface for all development environments may also be considered. The most significant issue that needs further clarification is one of compatibility, however. Compatibility is currently an issue in two areas. The first area relates to what actually constitutes an “EJB compatible” server. The second area is guaranteeing that EJB servers from different vendors seamlessly interoperate. No doubt exists that the current specification will go though some iteration to address some of these issues.
Summary
Enterprise JavaBeans is the cornerstone of what Sun terms as the “Java 2 Enterprise Edition” (J2EE). This platform consists of a suite of standard specifications for back-end services that deliver the required functionality for developing truly scalable, multithreaded, transaction-oriented, and distributed enterprise server applications. In this context, Enterprise JavaBeans has currently become one of the hottest technologies within the Java umbrella. As you learned in this article, EJB makes it easier for the developer to write business applications as reusable server components without having to worry about the nitty-gritty details. The Enterprise JavaBeans component architecture represents a giant step forward in simplifying the development, deployment, and management of enterprise applications.
This concludes this 8 part article on Enterprise JavaBeans. I hope you enjoyed reading this as much as I did writing it.
- Go to Container Managed Models-Enterprise JavaBeans - Part 1
- Go to Container Managed Models-Enterprise JavaBeans - Part 2
- Go to Container Managed Models-Enterprise JavaBeans - Part 3
- Go to Container Managed Models-Enterprise JavaBeans - Part 4
- Go to Container Managed Models-Enterprise JavaBeans - Part 5
- Go to Container Managed Models-Enterprise JavaBeans - Part 6
- Go to Container Managed Models-Enterprise JavaBeans - Part 7
- Go to Container Managed Models-Enterprise JavaBeans - Part 8